Language Understanding APIs
Language Understanding APIs
Semantic Analysis for Restaurant Reviews - 128 dedicated Semantic Models
Products -> Semantic Analysis for Restaurant Reviews

Semantic Analysis for Restaurant Reviews
- Get the On-Premise version with 0 cents / text (Big Data compatible)
- Trained and tested on hundreds of thousands of restaurant reviews
- Trained and tested on your data (you get ready-to-use technology)
- 128 Semantic models designed especially for restaurant reviews
- Capture 90% of the information contained within restaurant reviews
- Proven state-of-the-art accuracy (precision=90-95%, recall=70-85%)
What is inside Semantic Analysis for Restaurant Reviews
Semantic Analysis for Restaurant Reviews consists of 128 Semantic Models. Each Semantic model was especially designed, built, tested, and re-tested on hundreds of thousands of restaurant reviews from multiple sources. All presented Semantic Models work with an unparalleled precision of 90-95%.
Below, you will find a high-level view of all semantic models designed for restaurant reviews.
In other words, what type of information do we garner from reviews.
Client loyalty & Recommendations
Will he come back? vs. not come back?
Will he recommend it? vs. not recommend?
Overall good/satisfied. vs. Disappointed?
Is it good for kids? Couples? Special occasions? Meeting friends? Family meetings?
Restaurant’s General Opinions
Is the restaurant clean? Dirty? Renovated? Outdated? Smelly?
Need to wait for a table? Can’t book a table?
Need a reservation? Reservation problems?
Is it kids friendly? Has it got changing facilities, play area, got kids menu?
Critical (dangerous to the brand) opinions
Hair in Food, Food poisoning, Bugs/Insects,
Restaurant was not as advertised,
Dirty restaurant, Service unpleasant/unprofessional
Food Taste & Quality Opinions
Food was tasty? Delicious? Mediocre? Poor? Bad? Tasteless?
Low-quality ingredients? Fresh? Poorly presented? Healthy food? Greasy? Unappetising? Perfectly cooked?
Opinions about specific dishes
Was a chicken tasty? Ws spaghetti ok?
Were grilled vegetables crispy?
Was the dessert fabulous?
Food Variety & Selection Opinions
Vegetarian menu? Vegan options? Gluten-free options?
Good wine/drinks selection? Good beer selection?
How about the menu? Limited? Rich?
Service Opinions
Staff was friendly? Professional? Rude?
Waiting time was acceptable? Is delivery time quick?
Manager: friendly? Professional? Available?
Service was quick, slow? good?
Addons Opinions
Wifi - is it free? Is it fast?
Does parking have lots of spaces? limited? lack of parking?
Pet-friendly/unfriendly?
Is suitable for a wheelchair? Is there good ventilation? AC?
Price/Payment Opinions
Was it overpriced? Cheap, expensive? Was it worth them money?
Is there a service charge? Any additional fees? Bill problems?
Only cash payment?
Vibe Opinions
Nice vibe? Cozy, relaxing atmosphere? Pleasant? Unpleasant vibe?
Was it not welcoming?
Was the decor nice? Interior outdated?
If you want to get custom-made private API with different models, or receive more info about the custom On-Premise version with 0 cents/text (BIG DATA Compatible)
What this technology can do (for business/restaurant owners and for users/travelers)
1. AI powered travel search & discovery & chatbots (for users)
1.1. Restaurant Search personalization (for users/travelers)
Search based on your individual preferences matched with opinions of similar people to you and data from reviews
What is important to you? Personalize your search
Our AI remember these parameters while reading millions of reviews and find you the best possible place
- Intimate and romantic vibe
- Fast WiFi, quiet place for work
- No waiting time for table, fast service
- Handicap accessible
- Good place for kids, changing table, kids menu
- Nicely decorated place, clean, recently updated
- No crowded places, No busy places
- Many gluten free & vegan options
- more...
- Recommended for (based on reviews)
Meeting with friends, With children, Business meeting, Romantic date, Anniversary, To meet new people, For work (quiet place), Pet friendly - Favourite dishes (based on reviews)
Indian cuisine, Roasted meat, Tacos, Sandwiches, Vegetarian options, Vegan options, Gluten-free options, Grilled chicken, Grilled vegetables, Italian pasta, Sushi - more...
Our AI deeply analyzed 4.4 million reviews to match your personal needs and chose these places:
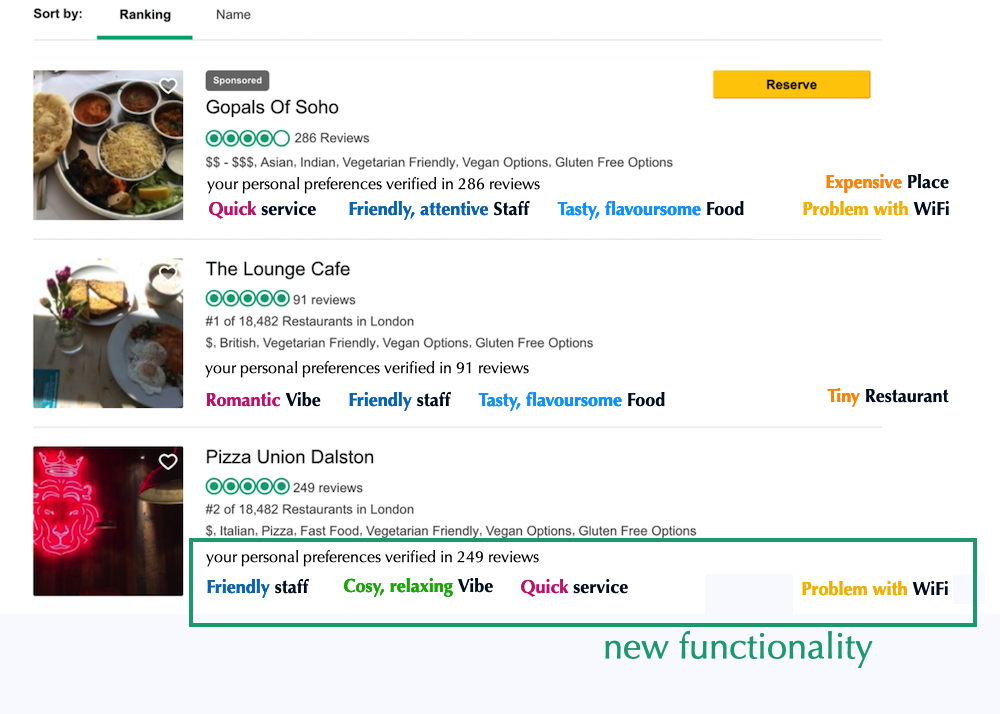
1.2. Travel chatbot fueled by reviews - Automatic learning of information and users opinions from reviews and using it in conversation.
Meet the Alchemist Foodie. He has eaten everywhere and he has read all reviews in the world (and he remembers them all).
He is patient and he can spare a moment to find you new interesting places.
Example 1:

Example 2:
Do you want me to make reservation for you?
Example 3:
1.3. Human-like (Semantic) summary of reviews (for Users)
Instead of reading thousands of reviews individually, you can see a semantic summary and get a feeling for what is contained within them in 20 seconds. You can click for specific information and see extracted sentences from reviews.
Restaurant
restaurant in generaldecor nice 33 renovated 18 clean 15reservation need reservation 17 need wait for the table 11
vibe pleasant 25 live music nights 19
kids have kids menu 15 have high chair 14 have play area 11 have changing facilities 9
Opinions & Recommendations
opinionoverall satisfied 34 will return 24 will recommend 9recommendation good for a date 14 good for meeting friends 13 good for family meetings 11
Service
stafffriendly 23 competent 11 understaffed 9 unfriendly 4 uncompetent 2servicegreat 28 quick 18 slow 5 food run out 4
managerpoor contact 8
Price
restaurantexpensive 13 overpriced 9 adequate price 6paymentservice charge not included 17 high service charge 14
Food
tastedelicious 41 mediocre 5menurich 28 drinks menu limited 13 limited 4
portionsbig, decent 17
qualityfresh, high quality 12 healthy 9
special diet vegan/vegetarian available 31 gluten free available 25
Favourite dishes
italian pasta delicious 21 big portions 20grilled chicken delicious 15
grilled vegetables delicious 12 big portions 8
Addons
wififree 13 problem 7 slow 4parkingsmall 19 not free 17
aclack of 8 no ventilation 5
handicapnot accessible 9
Other
deal breakersnoneThe automatic summary made from reviews - after processed by our API (no additional NLP/NLU/ML or post-processing needed).
The first no-block title (Restaurant, Food etc.) is a Category from our API, blue blocks (Opinion, Staff etc.) are Aspects, green and red blocks (decor nice, renovated etc.) is the Feature and Polarity (Feature is text, Polarity is color).
See the live demo of semantic summary made from hotel reviews (powered by our technology).
2. AI-powered new analytical dashboards (for business owners)
2.1. Automatic Conversion of Reviews into Recommendations/Tickets/Tips (for Business Owners)
First, you process all reviews of a given restaurant for a period of time (e.g. last 6 months) and extract important information with high accuracy. Then, it is easy to compare these results with other restaurants, and valuable patterns emerge.

Our AI deeply analyzed all 4489 of your reviews, compared with 1 200 000 reviews of similar businesses and extracted 11 Recommendations/Tips how you can improve your business:
 Train your waitstaff to be more friendly (8% complained in reviews) and more professional (7% complained) - read more and see reviews...
Train your waitstaff to be more friendly (8% complained in reviews) and more professional (7% complained) - read more and see reviews... Consider making portions bigger because "it's not worth for this price" (5% complained - compared to 2.5% average) - read more and see reviews...
Consider making portions bigger because "it's not worth for this price" (5% complained - compared to 2.5% average) - read more and see reviews... Install changing table in the toilet (5% complained) and improve kids menu (4% complained) to be more family friendly - read more and see reviews...
Install changing table in the toilet (5% complained) and improve kids menu (4% complained) to be more family friendly - read more and see reviews... Consider improving the speed of the WiFi (11% complained) and make it work more stable (5% complained) - read more...
Consider improving the speed of the WiFi (11% complained) and make it work more stable (5% complained) - read more...- Turn off the music a little bit, you can’t make a conversation (3% complained) read more and see reviews...
Compare your parameters with similar businesses
2.2. Human-like (Semantic) classification of reviews (for Business Owners)
Here, we focused on showing classified negative opinions critical to restaurant owners and presented on a brand reputation dashboard.

Slow service (5 mentions):
"We needed to wait for the order 30 mins!"
"Food is great, but very slow service..."
"waited with my friends 25 mins to order"
"great if you don't mind waiting"
"was hungry and waited almost an hour for the food"
By clicking on specific semantic category (here: Slow service) we get specific sentences/segments and "not the whole review" where people mentioned that the service was slow. We detect all the information that is correlated to slow service (e.g. "needed to wait", "if you don't mind waiting"), not just with keywords (e.g. slow, service). This is the advantage if you use Human-like Analysis (Semantic Analysis) instead of keywords.
3. Other solutions
3.1. Semantic Distribution out of 1000+ reviews (for users&business owners)
You can see what reviews are about in 10 seconds. By clicking on specific information, you can go deeper (data zoom-in) and display actual sentences (not whole reviews).
Our AI deeply analyzed 3344 Reviews and organized them for you
(so you do not have to read them all)
| People was the most satisfied with: | |
| Quick service | |
| Friendly, attentive Staff | |
| Adequate Price | |
| Tasty, flavoursome Food | |
| Cosy, relaxing Vibe | |
| People complained about: | |
| Restaurant dark, no light | |
| Food not tasty | |
| Problem with WiFi | |
| show me more... | |
3.2. Human-Like Client Loyalty Analysis (1-dimension deeper than Sentiment Analysis).
By understanding a review better, you are able to provide deeper and easier-to-understand analysis for your clients.
1. Sentiment Analysis (positive vs. negative, Black&White approach)
Positive vs. Negative
2. Human-like Analysis (semantic, COLOR approach)
Overall good/satisfied vs. Overall dissapointed
Will come back vs. Will not come back
Will recommend vs. Will not recommend
Language has color. Do not reduce it to black & white.
3.3. AI powered Automatic Review Report Generation (for travelers&business owners)
Information extracted by 128 Semantic Models is precise enough to create automatic text summary.
Natural Language Generation Summary from Reviews could look like this:
Our AI deeply analyzed all your reviews for the past 3 months, combined them with reviews of similar businesses and created this summary:
Almost everyone were satisfied with the service (in 87% of reviews) and friendly staff (72%), lot of them would come back (45 mentions) and will recommend this restaurant (33m.).
Reviews stats that restaurant is tiny (17 m.) but have romantic vibe (13 m.), which suits for a date (12 m.).
Unfortunately, customers complain about small portions (8 m.) and not enough spices in their food (5 m.).
Overall they think that it is expensive place (7 m.) but worth the money spend (13 m.).
read more...
| Semantic distribution summary out of text: | |
| Service great | |
| Friendly staff | |
| Would come back | |
| Will recommend | |
| Tiny Restaurant | |
| Romantic Vibe | |
| Good for a date | |
| Expensive Place | |
| Worth money spend | |
Want to talk more about these solutions?
How it works on a single review
Example restaurant review:
Simplified output after processing by Semantic Analysis for Restaurant Reviews:
| 1. | We are going to this place every sunday with my family |
recommendataion
good for family meeting +1
|
| 2. | I love chicken masala there and i was not dissapointed, delicious |
food: chicken masala
delicious +2
|
| 3. | We took pad thai as well and I must say it was not so tasty as other dishes | food: pad thai not tasty -1 |
| 4. | My wife and kids love there, they got a special kids menu, changing table and staff is friendly too |
kids
kids menu available +1
changing facilities available +1
service staff friendly +1 |
| 5. | As we were leaving the jazz band started to play and there was a lot of young people and you can feel the good vibe in the air |
vibe
live music nights +1
pleasant +1
|
| 6. | So, I recommend for a family, even for a friends meeting at evenings, do not recommend to a business meeting or romantic dinner) |
recommendation
good for family +1
good for meeting friends +1
good for family +1
not good for business meeting -1
not good for romantic evening -1
|
How we differ?
- You can use the SaaS version, or get the On-Premise version with 0 cents / text! (BIG DATA Compatible)
- High Resolution/richness of output - 120+ Semantic Models in each product
- Very high Fact Coverage of information contained within the review (state-of-the-art: 90%)
- Very high, Human-like Accuracy (state-of-the-art: precision=90-95%, recall=70-85%)
- Trained and tested on your data - we make sure that above parameters are maintained
- Very fast and cpu-effective! On-Premise version on Amazon AWS medium-cpu instance - up to 1 million reviews a day.
We specialize in creating dedicated Language Understanding APIs for specific reviews or other user-generated content. We focused in travel, food, apps, surveys, profanity & toxicity detection and prepared a set of Language Understanding APIs for these domains. We also develop private custom-made Language Understanding APIs for any kind of text (reviews, comments, or other user-generated content). Contact Us to discuss what is possible, or Send Us Your Dataset to see how it works on your data.
We stand by the statement that we detect more information than Watson or than any other Deep Learning solution and we are more accurate than Google in a specific domain. We are also much more cost-effective. And we allow the processing of as much data as you want with no additional cost (0 cents / text).
This is possible because we created the next-generaion process of developing NLU systems in which we can build Semantic Models 10 x faster. It is designed from the ground up to process reviews and other user-generated content, not proper english texts. It is the result of 13 years of experience in NLP/NLU, 8 years in processing reviews, and more than 50 implementations (2007-2020) in companies, corporations, and startups of NLP/NLU systems and Language Understanding APIs to process reviews and other user-generated content.
We are passionate and proud of our technology and aim to provide the optimal technology for reviews and other user-generated content. We will be happy to help you implement your brilliant ideas and discover what is possible.
1. Sentiment Analysis & Concept/Keyword/Topic Analysis - Current tech available
| "Breakfast was tasty" | => | Breakfast: positive |
| "Breakfast was huge" | => | Breakfast: positive |
| "Breakfast was not included" | => | Breakfast: negative |
| "Breakfast was very tasty but limited choices" | => | Breakfast: neutral |
| "Breakfast was delicious but you had to pay extra" | => | Breakfast: neutral |
2. Semantic Analysis - Unicorn NLP (new Language Understanding APIs)
| "Breakfast was tasty" | => | Breakfast: tasty |
| "Breakfast was huge" | => | Breakfast: plenty options |
| "Breakfast was not included" | => | Breakfast: not included |
| "Breakfast was very tasty but limited choices" | => | Breakfast: tasty | poor, limited |
| "Breakfast was delicious but you had to pay extra" | => | Breakfast: tasty | not included |
Language has colors. Do not reduce it to black & white.
Technological differences of Unicorn NLP Cognitive Learning solution (compared to other NLP/NLU/ML/DeepLearning solutions):
- High Resolution/depth of output, richness of output, what different type of information we capture out of reviews - state-of-the-art: 120+ dedicated semantic models in each Semantic Analysis Product
- Very high Fact Coverage (state-of-the-art: 90%) - percentage of pertinent information we extract from reviews
- Very high, Human-like Accuracy - state-of-the-art F1: precision=90-95%, recall=70-85%
- Detailed, easy-to-use, and human-friendly Semantic models (e.g., comfy room, spacious room, tasty breakfast, will come back) instead of statistical models (e.g. room - confidence: 0.84623, score: 0.735267) or grammatic models (e.g. NS, VP, ADV)
- Very fast! We are much much faster than any deep learning or any other solution. Highly optimized technology was very important for us from the beginning. To show you how much, take this example: On a Amazon AWS medium-cpu instance we process up to 1 million reviews a day.
Other differences:
- You can get the on-premise version with no maintanance fees and 0 cents/text
- No linguistic or machine learning expertise required to implement it into your product/system! Output is simple enough to be used by anyone and even simple enough to be displayed to the user directly (no post-processing needed, no configuration required, most solutions can be implemented in days)
- All data extracted by our tech makes sense - we do not provide hard to understand keywords with confidence and some of them do not make sense. Each Semantic Model is actionable data (tasty breakfast, wifi does not work, staff was unfriendly, elevator not working, etc.). Each Semantic Model was built and tested on hundreds of thousands of hotel reviews. Each Semantic model consist of between a hundred and a thousand of ways to express concrete situation. That is why you do not have to configure it to your data.
More about Unicorn NLP Technology
What is a Semantic Model
The semantic model is the newest approach to information extraction models where boundaries of those models are not determined by the structure of a language (or grammar, or used words), but the type of information you are detecting. It does not matter how the user writes an opinion about a specific object, e.g. “breakfast was a joke”, “Muffin and cold coffee is not a breakfast”, “Breakfast wasn’t included as written”, our semantic model still detects it and provides structured-data. With "breakfast" example, it is relatively easy to provide a shallow analysis (e.g. Sentiment Analysis) with the current NLP techniques. If you are looking for more sophisticated information (e.g. is it safe?, is it handicap friendly?, will someone come back?, Is it sustainable? Is it pet-friendly?) the situation gets more complicated. Current techniques provide a part of this information and their accuracy relies on the keywords used in reviews. Users are very creative in the reviews and they are not using a keyword approach. Let’s take one example. If we want to answer the question “is it safe?”, you need to capture a lot of information from reviews without common keywords safe/dangerous. In practice, they write this in tens or hundreds of ways: e.g. “there was a lot of drunken people outside”, “I did not feel good because of the neighbors”, “someone yelled in the night and the front desk lady did nothing”. We believe that if the human can understand what is written in the review, then technology should detect it as well. That is why we call them Semantic Models, not information extraction models.
Where and how we develop Semantic Models
Our Unicorn NLP Cognitive Learning Environment is a place where we design and precisely craft all the semantic models. It is a perfect combination of human and computer intelligence. It is the result of 13 years of experience in the NLP/NLU field and 50+ implementation in 2007-2020. It is the secret sauce of our technology, and it allows us to deliver the best technology in the world for reviews and other user-generated content. Statistical algorithms provide the data based on the processing of hundreds of thousands of reviews, but the humans are making all the crucial decisions. Human does not only annotate the data (like in machine learning approach), but also create semantic boundaries, semantic rules, domain-specific dictionaries, describe common domain-specific misspellings and grammar errors, and whatever it takes to achieve precision=90-95%. Given the pace of AI development, this is a significant advantage in information extraction (in NLP/NLU), and it will be appropriate for the next decade. Think about our environment as a way of creating tens of thousands of very precise, hand-crafted semantic rules but with an AI as an assistant rigorously validating new ideas and marking parts of algorithms and semantic code that needs improvement. AI assistant provides new ideas based on constant simulations on real data and tens of statistical tools.
We designed a unique semantic programming language (QL4Reviews) to extract information from reviews and other user-generated content. With this programming language, you build semantic models ten times faster than in other current technologies. Every Semantic Model is programmed in QL4Reviews and consists of 50-2000 lines of semantic code. Heavily optimized engine allows processing through 150+ Semantic Models on 1 medium-CPU Amazon AWS instance - 1 million reviews a day. The speed of the core engine was essential for us from the beginning. It helps us daily speed the process of development and make several iterations and validation on data a day.
How to process non-English Reviews
Our technology is designed from the ground up to process reviews and other user-generated content, not proper-grammar texts. It's resistance to errors allows processing also machine-translated reviews/texts (via Google Translate or Microsoft Translate). This approach provides almost as good results as processing English reviews but there is no need to rewrite and maintain semantic models into other languages. Consequently, it is a much more cost-effective solution, and it is easier to maintain and scale (using Google Translation API allows you to process 105 languages on day one).
Read more & See demo: Processing machine-translated non-English Travel Reviews
Are we another NLP/NLU API?
This is not just another limited black box that you still need to configure to your data, and learn how to use it. You get dedicated Language Understanding API with a human-like accuracy, which is train&tested on your data. We redesigned every layer of technology and we wanted to address the biggest challenge in the NLP/NLU industry. We wanted to change the way you use and think about Natural Language Understanding API. In our opinion, if you are using NLP API, you should not get your hands dirty and spend inordinate time thinking about how to best implement this API into your application. We wanted to hide all the NLP complexity inside the system and provide you ready-to-use data. We believe that NLP API should be simple and easy to use without linguistic, machine learning or other expertise. You do not need to spend weeks on improving the accuracy of "domain-independent" NLP API, to adjust to Your domain or to make decisions about complex output parameters. Getting output parameters like confidence (e.g. 0.7852) or polarity (e.g. 0.4352) or keywords detected (e.g. friendly, 0.6786; disappointed, -0.7564) gives every developer problems and frankly, they are not standard or predictable. They are rather a consequence of used technology inside, and putting these parameters for the output in our opinion, is the way to leave configuration and responsibility for decision-making to You. We believe in simple human-like output where a human can understand what this API detected. We believe that we have developed excellent semantic models for specific domains, so you can get tailored results and focus on your business. We position ourselves as a read-to-use technology, not a standard API that is a tool that you need to configure and train to your data.
What's next
If you want to get custom-made private API, or receive more info about the custom On-Premise version (with 0 cents/text),
or want to discuss what is possible
If you want to test it or see how it works on your data, send us a dataset
(we do not collect your data)